
دراسة من انفيديا : النماذج اللغوية الصغيرة هي مستقبل الذكاء الاصطناعي الوكيلي

بتاريخ 2 يونيو 2025، نشر باحثون من NVIDIA بحث بعنوان "Small Language Models are the Future of Agentic AI" ، ودي ورقة بحثية بتدافع عن فكرة إن النماذج اللغوية الصغيرة (SLMs) هي الأفضل لتطبيقات الذكاء الاصطناعي الوكيلي (Agentic AI). الورقة بتقول إن الـ SLMs كفاية قدراتها، أكتر ملاءمة عمليًا، وأرخص اقتصاديًا لمعظم المهام اللي بتعتمد عليها الأنظمة دي، زي التنبؤ والتخطيط والتحكم في الأدوات. هيخاطب الجمهور التقني، هحافظ على التفاصيل التقنية زي أسماء النماذج والحجج العلمية.
مقدمة عن الورقة وأهميتها
الذكاء الاصطناعي الوكيلي (Agentic AI) ده نظام بيستخدم نماذج لغوية كبيرة (LLMs) زي GPT-4o أو Claude-3.5-Sonnet عشان يقوم بمهام متخصصة بشكل متكرر، زي إدارة العمليات أو حل المشاكل المعقدة . لكن الباحثين بيقولوا إن الـ LLMs دي زيادة عن الحاجة، وإن الـ SLMs (النماذج أقل من 10 مليار باراميتر تقريبًا) هيبدلوها في معظم الحالات. الورقة بتعرف الـ SLM إنها نموذج يقدر يشتغل على جهاز مستهلك عادي مع تأخير منخفض، بينما الـ LLM أكبر وبتحتاج بنية تحتية سحابية مركزية . الرؤية الرئيسية هي: الـ SLMs قوية كفاية ، أكتر ملاءمة عمليًا ، وأرخص للأنظمة الوكيلية، وده هيؤدي لتحول جزئي أو كامل من الـ LLMs للـ SLMs.
الورقة بتستند على إحصائيات سوقية: سوق الـ Agentic AI وصل 5.2 مليار دولار في 2024 ومتوقع يوصل 200 مليار بحلول 2034 ، لكن الاعتماد على الـ LLMs بيرفع التكاليف، وده يمكن يقل لو استخدمنا الـ SLMs في أنظمة هجينة (heterogeneous systems) اللي بتستدعي نماذج مختلفة حسب المهمة.
حجج الورقة الرئيسية لصالح الـ SLMs
الباحثين بيقدموا حجج مدعومة بأمثلة تقنية حديثة عشان يثبتوا إن الـ SLMs هي المستقبل:
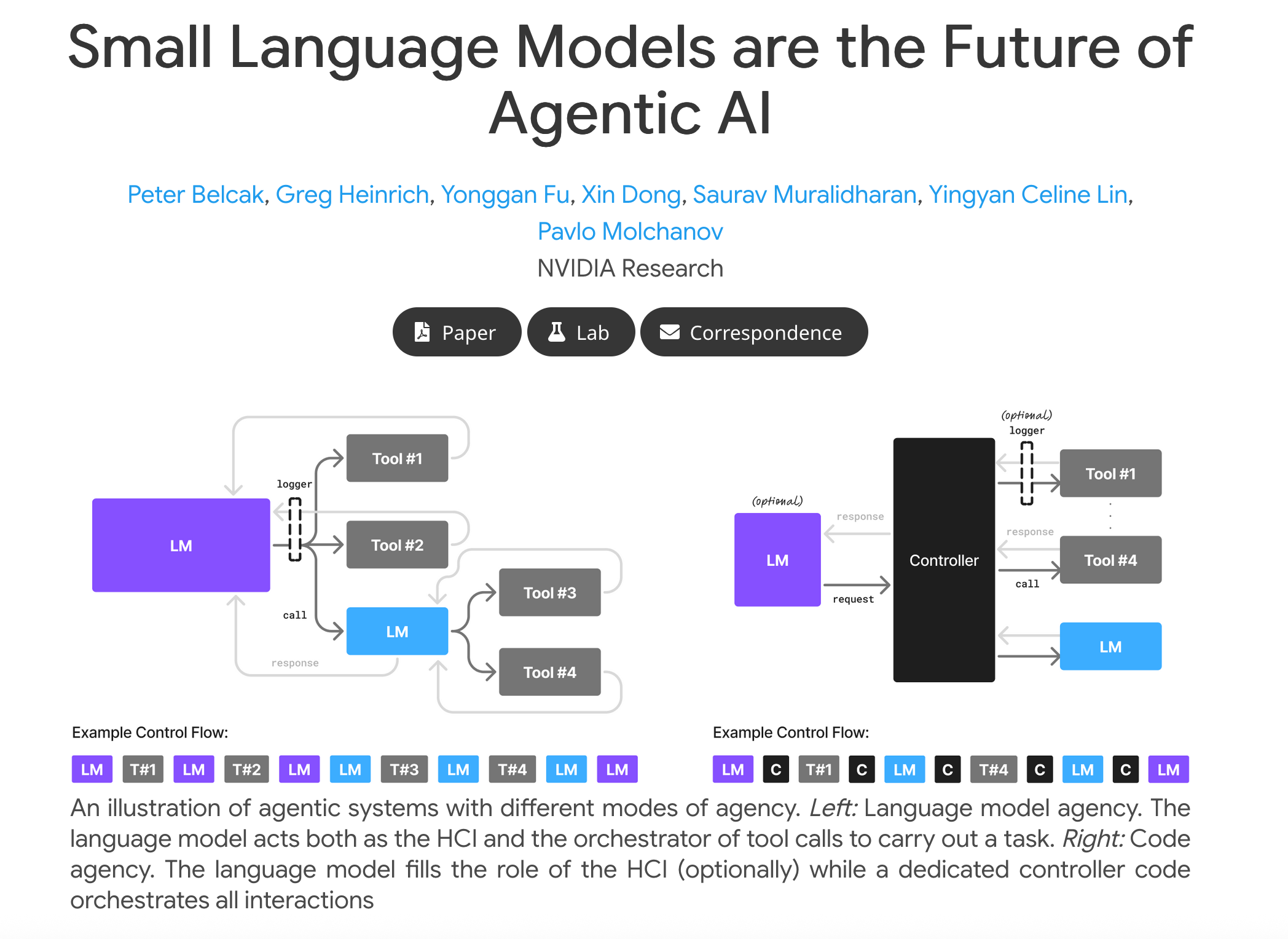
قوة الـ SLMs في المهام الوكيلية : الـ SLMs وصلت مستويات أداء قريبة من الـ LLMs في الفهم الشائع (commonsense reasoning)، استدعاء الأدوات (tool calling)، وتوليد الكود (code generation). مثلًا، Microsoft Phi-3 (7B) بيحقق أداء في فهم اللغة وتوليد الكود مشابه لنماذج 70B، مع سرعة أعلى 15 مرة . NVIDIA Nemotron-H (2-9B) هجين Mamba-Transformer بيضاهي 30B في اتباع التعليمات مع توفير في FLOPs بنسبة 10 أضعاف . كمان، Huggingface SmolLM2 (125M-1.7B) بيطابق 70B من عامين سابقين في tool calling . الورقة بتذكر تقنيات زي Toolformer (6.7B) اللي بيستخدم API عشان يفوق GPT-3 (175B) في الرياضيات .
التوفير الاقتصادي : الـ SLMs أرخص في الاستنتاج (inference) بنسبة 10-30 مرة في الوقت والطاقة مقارنة بالـ LLMs . مثلًا، نظام NVIDIA Dynamo بيسمح بتشغيل SLMs على الحافة (edge) بتأخير منخفض، وfine-tuning زي LoRA أو DoRA بياخد ساعات GPU قليلة . الورقة بتؤكد على التصميم المعياري (modular design) اللي بيسمح بتجميع نماذج صغيرة متخصصة بدل نموذج عملاق واحد.
المرونة العملية : الـ SLMs أسهل في التدريب والتعديل، مما يسمح بتخصيص لسوق معين أو قوانين محلية . ده بيؤدي لـ "ديمقراطية" الذكاء الاصطناعي، حيث يقدر أكتر ناس يطوروا نماذج، مما يقلل التحيزات ويزيد الابتكار.
الاستخدام الضيق في الأنظمة الوكيلية: الأنظمة دي بتقتصر على مهام متكررة، مش محتاجة قدرات عامة زي الـ LLMs. مثلًا، الـ SLMs أفضل في التوافق السلوكي (behavioral alignment) مع تنسيقات محددة زي JSON لtool calls . كمان، الأنظمة الوكيلية هجينة طبيعيًا، فبتقدر تستخدم SLMs للمهام الفرعية وLLMs للرئيسية . وأخيرًا، التفاعلات الوكيلية مصدر بيانات جيد لتدريب SLMs متخصصة بتكلفة منخفضة.
ردود على الآراء المضادة
الورقة بترد على انتقادات زي إن الـ LLMs أفضل في فهم اللغة العام بسبب قوانين التوسع (scaling laws) . الرد: الـ SLMs تستفيد من معماريات مختلفة زي Hymba-1.5B اللي بيحقق سرعة 3.5 مرات أعلى من 13B ، وfine-tuning رخيص يحل المشكلة. كمان، انتقاد إن الـ LLMs أرخص بسبب الاقتصاد الجماعي (AV2) بيتم رفضه بفضل تقدم في جدولة الاستنتاج زي Dynamo .
عوائق التبني وخوارزمية التحويل
العوائق الرئيسية: استثمارات هائلة في بنية LLMs (57 مليار دولار في 2024) ، وتركيز على معايير عامة بدل وكيلية. الورقة تقترح خوارزمية تحويل : جمع بيانات من استدعاءات الوكيل، تصفيتها، تصنيف المهام، fine-tuning SLMs زي LoRA، ثم تكرار .
دراسات حالة وخاتمة
في دراسات حالة زي MetaGPT (60% قابلة للتبديل) وCradle (70%)، الورقة بتثبت إمكانية استبدال LLMs بـ SLMs . الخاتمة: التحول ده مش بس تقني، لكن أخلاقي لتقليل التكاليف البيئية.